ここでは主に、ChatGPTのようなチャット型のAIについて中高生にもわかるような説明を目標としています。
※ただし、この記事をChatGPTに読み込ませてみたら、「ここは不適切」「今現在はこうなってる」といった指摘を多数されてしまいました。疑問に思う部分はご自身で調べてみてください。この記事はあくまで概要を示しているだけです。
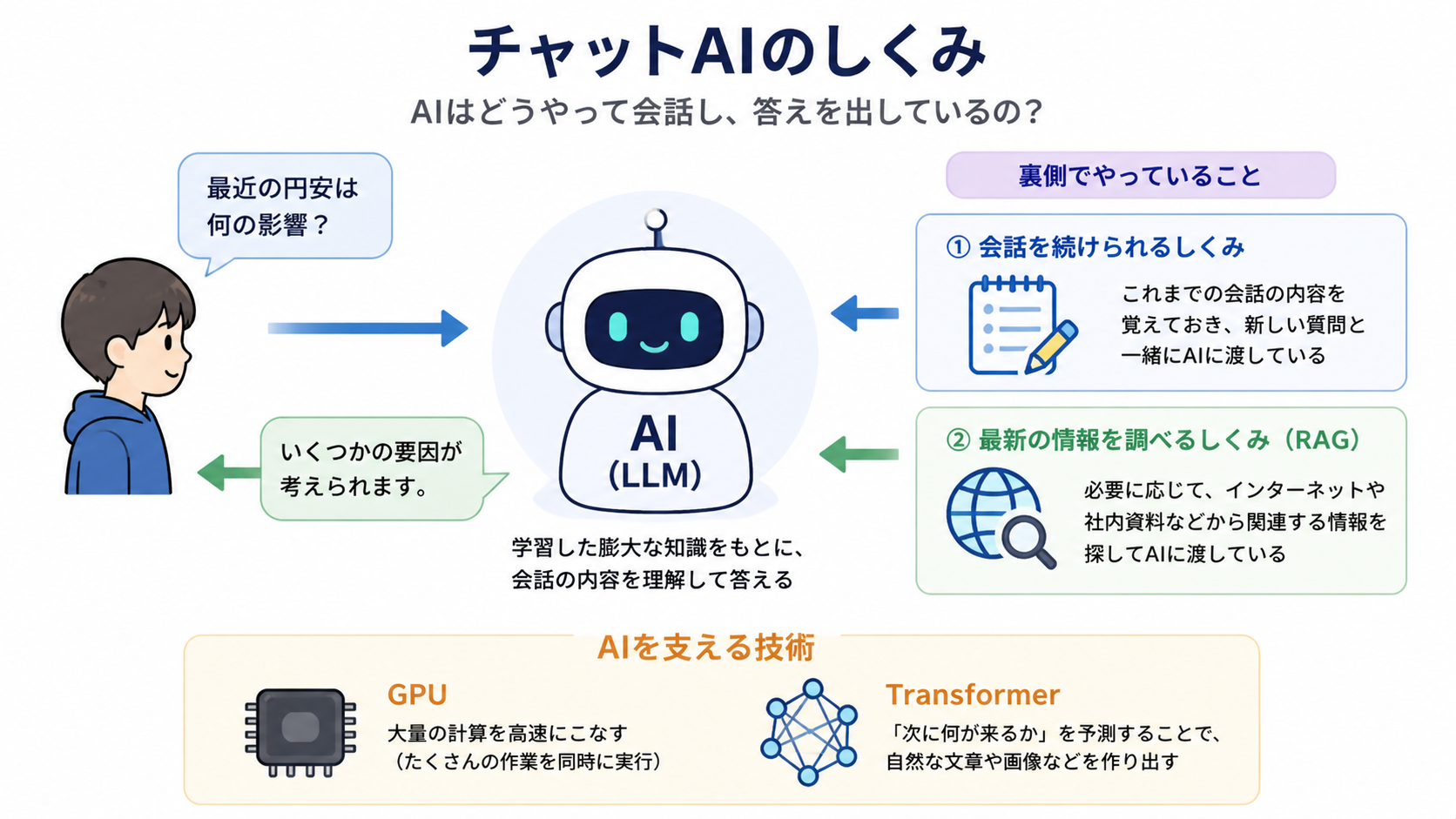
チャットAIの仕組み
LLMは「超物知り」
LLMとは、ChatGPTのような会話AIの「脳」部分のことです。
脳部分とは言っても、人間の脳とはかなり違いますよ。人間の脳には記憶がありますが、LLM自体にはないと考えてよいです。「あなたと過去に会話した内容」は一切覚えていないのです。
これとは矛盾するようですが、その一方で、「学習済みの知識」は焼き付いています。これは記憶というよりも「身についたスキル」に近いものです。例えるなら、自転車の乗り方を一生忘れないのに似ています。
イメージとしては、世界中の本・ニュース・ウェブサイトをすべて読んだことがある、超物知りです。何を聞いても、読んだ内容をもとに答えてくれます。この部分を学習すればするほど、より物知りになっていきます。
ただし、LLMには二つの大きな弱点があります。
- 弱点①:過去の学習でしか答えられない
あるLLMが学習し終わったのは、たとえば2024年の春です。それ以降に起きたことは何も知りません。「昨日のニュースは?」と聞いても答えられません。 - 弱点②:話が終わると全部忘れる
LLMは、一つの会話を終えた瞬間に会話の内容をすべて忘れてしまいます。次の質問をすると、前の内容を忘れています。
「ChatGPTもClaudeもちゃんと会話を続けられるじゃないか!」と言うかもしれませんが、LLMとは別の仕組みでこれを行っています。
ともあれ、LLMをいかに鍛えるか(学習させるか)は、AIを便利に使う目的のためには大きな部分を占めます。世界のありとあらゆる情報を学習させておけば、(ある程度)あらゆる質問にも答えられますね。
なぜ会話が続けられるのか?
では、なぜ会話が続けられるのでしょうか?
これはLLMを利用するアプリ側(AIエージェントなど)が工夫しているからです。簡単に言えば、これまでの質問と回答をアプリがそのまま覚えておき、ユーザが新たな質問をする時に、一緒にLLMに渡しているのです、こっそりと。
1)あなた:俳優のAさんは既婚者でしたっけ?
LLM:はい
※この時点でLLMは、俳優のAさんの結婚について聞かれたことを忘れてしまう。
2)あなた:相手はどんな人です?
※誰の「相手」かを特定していないが、文脈から当然、俳優のAさんの結婚相手について聞いている。
LLM:歌手のBさんです。
※この答えを返すには、前の会話を覚えていなければならない。
2)の質問において、同時にLLMに渡されているのは、1)の会話の内容なので、LLMに記憶がなくても的確に答えられるわけです。
しかし、会話が長くなると、毎回大量の文章を渡さねばならず、処理が大変になるので、途中で自動的に「これまでの会話内容を要約して」とLLMに頼んでおき、次からは「これまでの会話内容メモ」が渡されることになります。
これがチャット型のAI利用において裏で起こっていることです。
しかし、古い情報しかない
先ほど、このLLMの学習終了が2024年春だとすると、それ以降の知識はないと書きました。しかし、最近の時事ニュースに関する質問にもAIは平然と答えてくれますね。これはどうしてでしょう?
ここでRAG(Retrieval-Augmented Generation、検索拡張生成)という概念が登場します。難しそうな感じですが、実際には簡単です。
さきほど、会話を続けるために、「質問のたびに過去の会話内容か、そのメモが同時に渡される」と書きました。これに加えて、別のものも渡されています。
例えば、LLMは最近のニュースや、(社内の管理まで任せている場合には)社内情報については確実に知りません。これについてLLMが的確に答えられるように、裏でこっそり「適切な資料」を渡しています。これがRAGと呼ばれるものです。
この資料としては、ウェブ上のあらゆる記事かもしれませんし、管理を任せている社内資料かもしれません。
ウェブ上の記事についてですが、例えば、ChatGPTのようなAIシステムでは、あらゆるウェブサイトを定期的にチェックしています。が、単純に「この記事はこういうことを書いているようだ」という印をつけておく程度です。
※しかし、これらのデータをもとにLLMの学習データをすぐに強化することはできません。LLMの学習には膨大なコストと時間がかかるため、ウェブの記事を見るたびにLLM自体を更新することは現実的ではありません。この巡回は、あくまでRAGのための資料として保管しているだけです。つまり、LLM自体は2024年春の知識のままです。
このやり方としてはもちろん、Google検索などの一般的な検索において想像できるようにキーワード(語句)で印をつけることもあるし、ベクトル検索という手法を使うこともあるようですが、ここでは詳細は説明しません。単純に、文章全体の意味を数値化して近いものを探せるようにするといったイメージです。
そして、こういった会話が可能になります。
あなた:最近の円安は何の影響でしょうか?
※「円安」というキーワードからRAGが発動して質問と同時に資料をLLMに渡す。
LLM:**や**と考えられます。
社内資料といった文書についても同じようなことが行われているわけです。
なぜLLMは質問に答えられるのか?
膨大な学習データを使って、人間からの質問にAIは答えられるわけですが、なぜ答えられるのでしょうか?人間のように意味がわかっているわけではないのです。AI議論で有名な例として「中国語の部屋」というものがあります。
中国語を全く知らない人が部屋に閉じ込められている。
外から中国語の質問が入ってくる。
部屋の中には、「この記号が来たら、この記号を返せ」という超巨大マニュアルがある。
その通り返すと、外の中国人から見ると、「完璧に中国語を理解して会話している」ように見える。
しかし本人は、中国語の意味を全く理解していない。
他の説明としてはこんなものがあります。
LLMは、「次に来そうな言葉」を当てる練習を、世界中の文章を使って何兆回も行ったAIです。最初は全然当てられませんが、大量の文章を読むうちに、
- 人間の会話
- 知識
- 文章の流れ
- 質問への答え方
のパターンを身につけていきます。その結果、人間から見ると「理解している」ように見えるのです。
あるいはこんな説明もあります。
例えば:
「今日はとても──」
→ 「寒い」「暑い」などを予測
「猫は魚を──」
→ 「食べる」を予測これを膨大に繰り返した結果、単なる単語ではなく、
- 会話
- 知識
- 文法
- 推論っぽいもの
まで身についてしまった。
他のAIの仕組み
ここまでチャット型AIの仕組みを説明してきましたが、最近は動画生成、画像生成、音楽生成など、様々な分野のAIが登場しています。これらは、チャット型のAI(LLM)とは全く別の仕組みです。が、共通する部分が2つあります。
- 莫大な計算量を高速にこなすGPUユニット
- Transformer(トランスフォーマー)と呼ばれる設計に基づいていること(2017年にGoogleが発表した、AIの性能を飛躍的に高めた画期的なアイデア)
AIを推し進めたGPU
もともとコンピュータには、CPU(Central Processing Unit)というものしかありませんでした。これは、一人の小人さんが命令(人間の書いたプログラム)に従って複雑なことを何でもやってくれるというイメージです(最近では4人とか8人とかの小人さんが入っているものが多いです)。
しかし、特にゲーム市場が発展すると、CPUでは処理しきれない膨大な画面処理が必要になり、これらの小人さんでは手が足りなくなりました。彼らは非常に賢くて何でもこなしますが、人数はあまり増やせません。
そこで、GPU(Graphic Processing Unit)というものが登場しました。これは、あまり賢くないけれども、単純作業をもくもくとこなす小人さんが数十人・数百人入っているようなイメージです。膨大な画面処理を大人数の小人さんが力づくで行うというイメージです。
ところが、GPUが登場すると、画面描画以外にも使えることがわかってきました。一つはビットコインマイニングと呼ばれるものです。これも、単純作業をもくもくとこなすことが必要です。そして、もう一つがAIだったというわけです。
もともとのGPUの役割は画面の各ピクセルに色をつける作業ですが、隣のピクセルのことを気にせずに自分の担当だけをひたすらやればいい単純作業です。だから賢くなくていいのです。AIの計算も、実は同じ「単純作業の大量繰り返し」という性質を持っていました。
このように、GPUはゲームなどの画面描画に特化したものとして開発されたのですが、最近ではAI利用のためにさらに推進されています。このため、特にIntelのようなCPUメーカーは、AIブームによってNVIDIAに主役の座を奪われた格好で、業界の勢力図が大きく変わっています。
NVIDIAはゲーム用GPU会社でしたが、AI研究者がGPUの有用性に気づいた2010年代にいち早くAI向けの開発環境を整備したことで、結果的にAIブームの最大の勝者となりました。
Transformer
さて、様々な種類のAIに共通するもう一つとして「Transformer(トランスフォーマー)と呼ばれる設計に基づいていること(2017年にGoogleが発表した、AIの性能を飛躍的に高めた画期的なアイデア)」と書きましたが、Transformerの詳細は非常に専門的なのでここでは省きますが、核心だけ言うと「文章・画像・音楽のどれを扱う場合でも 次に何が来るかを予測する」という作業を行っています。
共通点
├── アーキテクチャ:Transformerベース
├── 学習方法:大量データでパターンを学ぶ
├── ハードウェア:GPUで大量並列処理
└── 本質的な作業:「次に何が来るか」の予測違う点
├── 学習データの種類(テキスト・画像・音楽)
├── 出力の形式
└── 細かい設計の工夫
コメント