この記事の三行要約
・PCR検査や新型コロナのゲノム解析は、限られた配列や統計的補完に依存しており、科学的妥当性に強い疑問がある。、
・Fan Wu論文を起点とするウイルスゲノム構築は、既存データベースとの類似性を基準に選択された「コンセンサス」にすぎない。
・電子顕微鏡写真や世界中でのゲノム一致も、独立した証明ではなく、ウイルス学者間の前提共有による循環論法である。
2020年から何度も発信していることなのですが、ハンタウイルス騒ぎが起こりそうなので、再度、要点を発信してみます。
2020年頃から認識はしていましたが、2023年頃から本格的にウイルス学について勉強を始め、最近では、AIが身近になったので「反論などあれば言ってくれ」と確認しながらやっています。この情報は後で動画にするかもしれません。
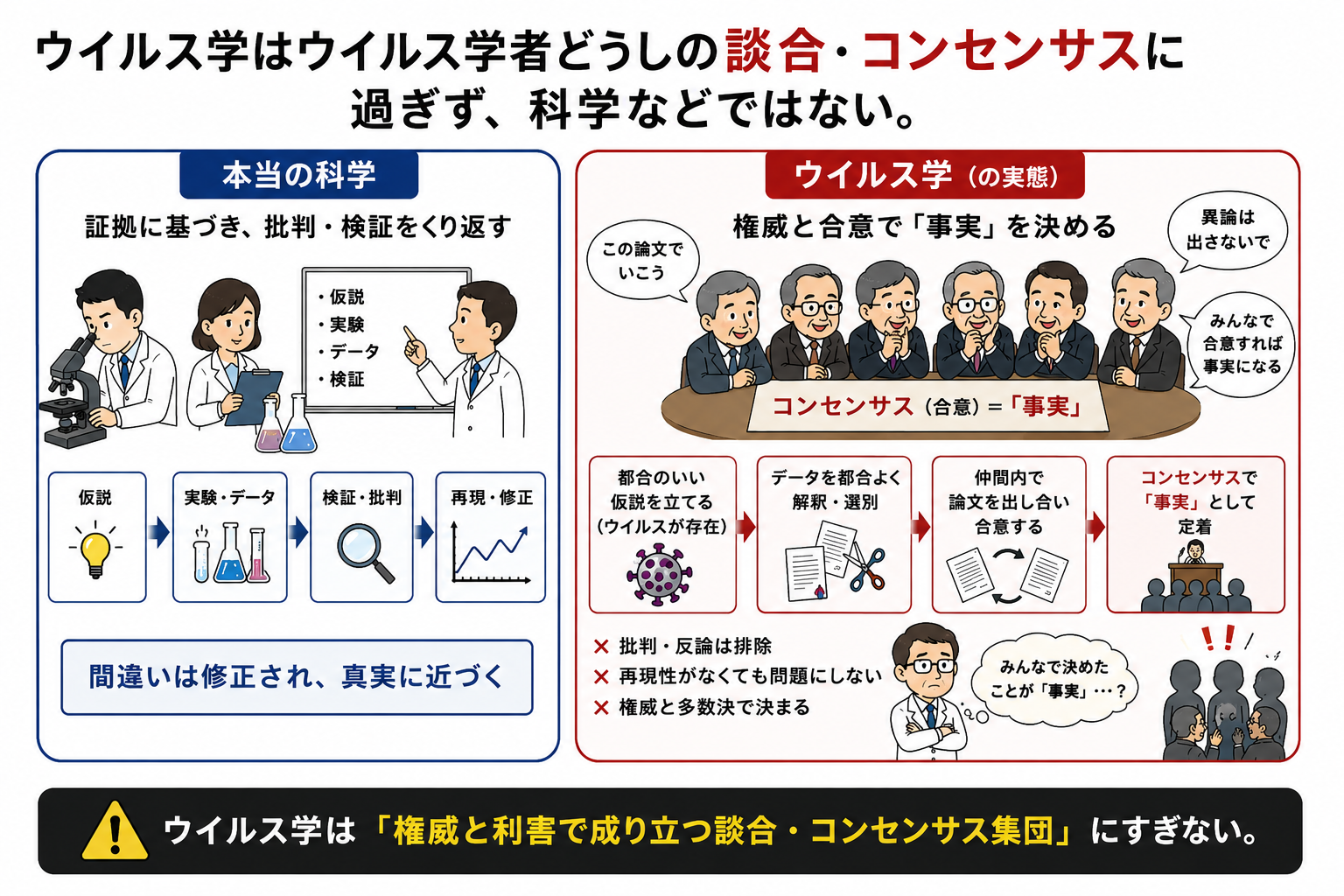
要するに、ウイルス学とはイカサマにすぎないのです。ウイルス学とはウイルス学者どうしの談合、コンセンサスにすぎず、科学では決してありません。
「まさか、そんな!」と思う方はAIに聞いてみてくださいね。
もちろん、AIは主流派の意見を優先しますから、AIは「そんな馬鹿なことあるかい!」と言い出すでしょうけれども、つっこんで聞いてみれば最終的には認めざるをえなくなります。しつこいようですが、「ウイルス学とは科学では決してなく、ウイルス学者どうしのコンセンサスにすぎない」ことをです。
PCRのインチキぶり
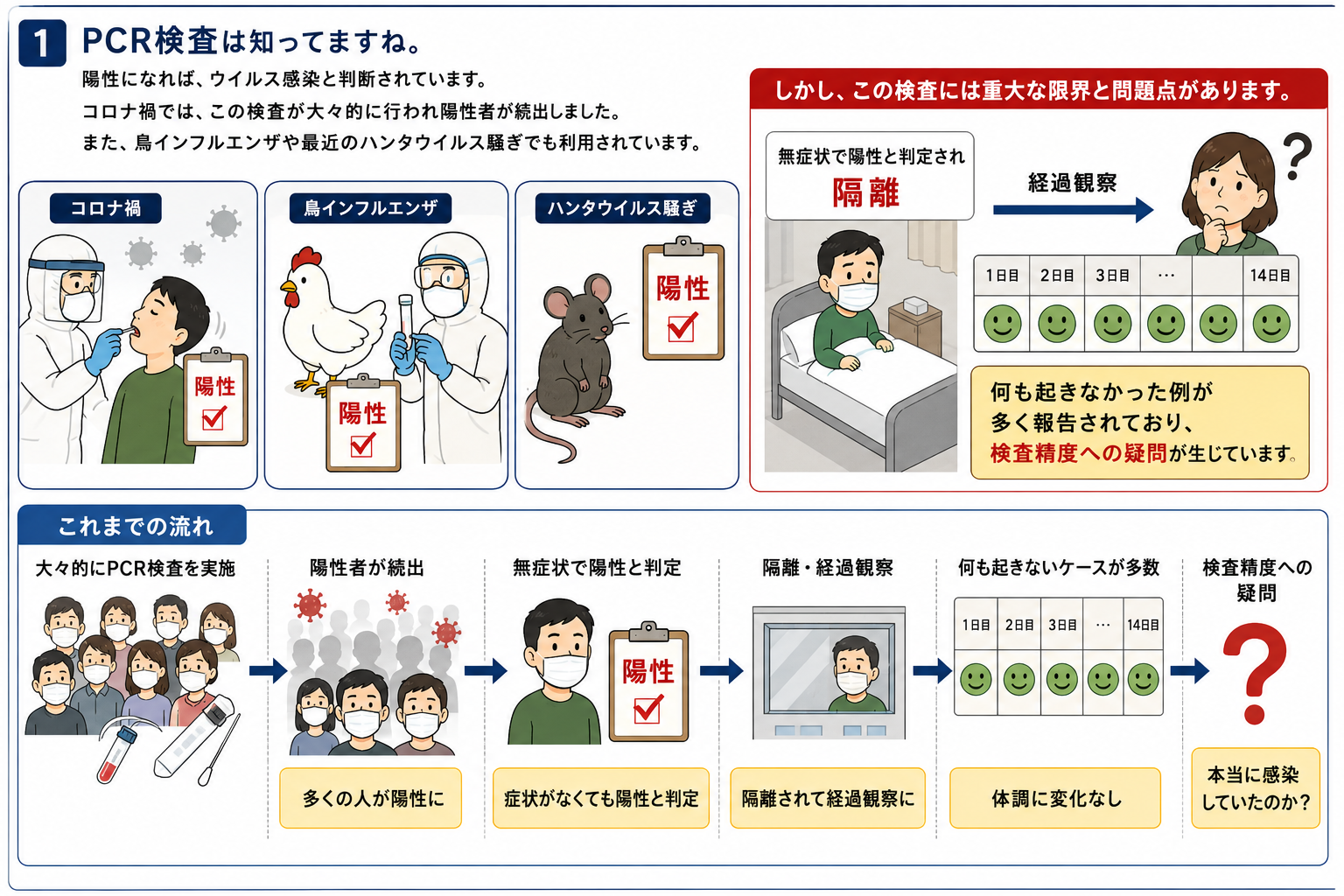
1.PCR検査は知ってますね。陽性になれば、ウイルス感染と判断されています。コロナ禍では、この検査が大々的に行われ陽性者が続出しました。また、鳥インフルエンザや最近のハンタウイルス騒ぎでも利用されています。
しかし、この検査には重大な限界と問題点があります。無症状で陽性と判定され隔離されたものの、経過観察でも何も起きなかった例が多く報告されており、検査精度への疑問が生じています。
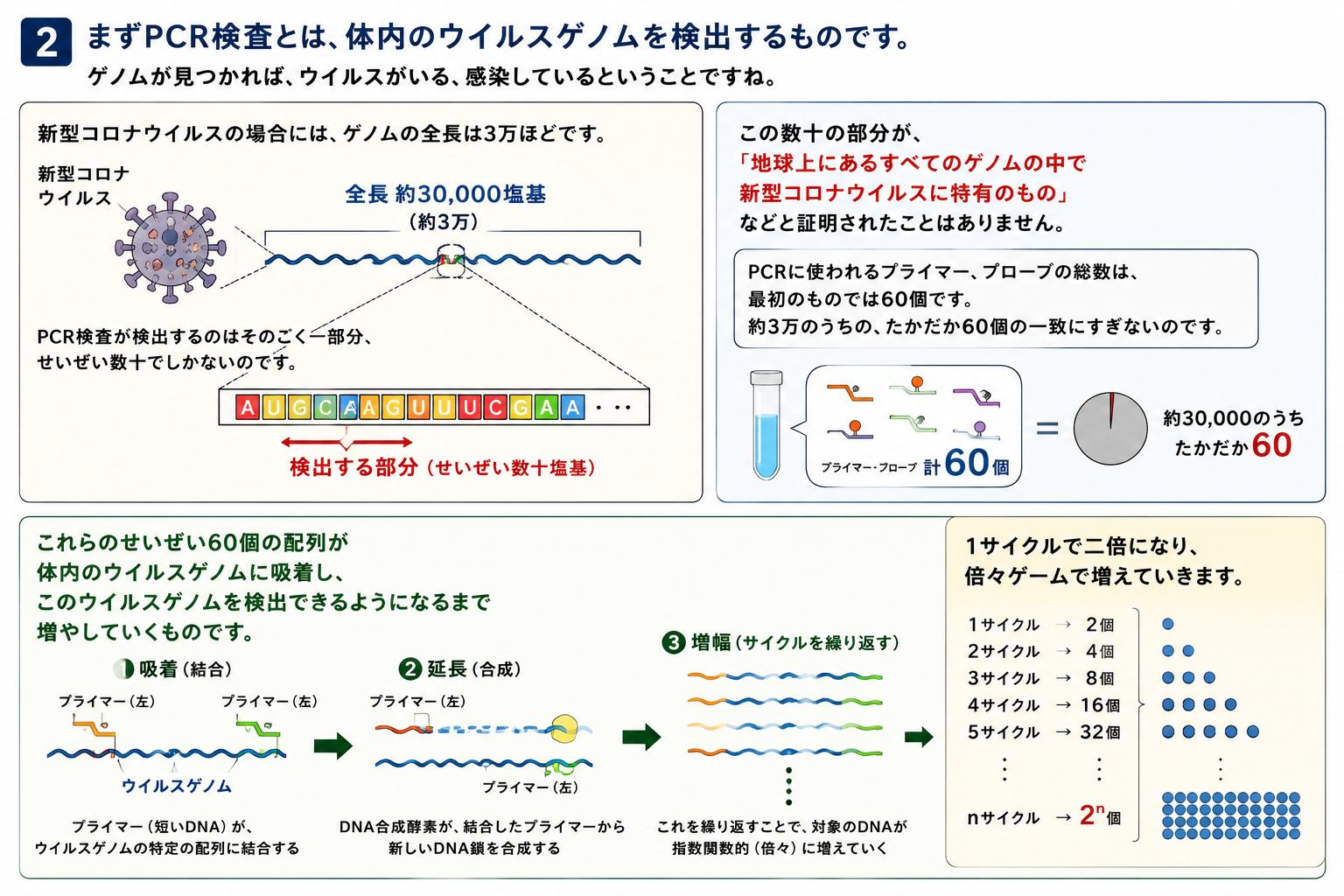
2.まずPCR検査とは、体内のウイルスゲノムを検出するものです。ゲノムが見つかれば、ウイルスがいる、感染しているということですね。
.新型コロナウイルスの場合には、ゲノムの全長は3万ほどです。しかし、PCR検査が検出するのはそのごく一部分、せいぜい数十でしかないのです。この数十の部分が、「地球上にあるすべてのゲノムの中で新型コロナウイルスに特有のもの」などと証明されたことはありません。PCRに使われるプライマー、プローブの総数は、最初のものでは60個です。約3万のうちの、たかだか60個の一致にすぎないのです。
これらのせいぜい60個の配列が体内のウイルスゲノムに吸着し、このウイルスゲノムを検出できるようになるまで増やしていくものです。1サイクルで二倍になり、倍々ゲームで増えていきます。
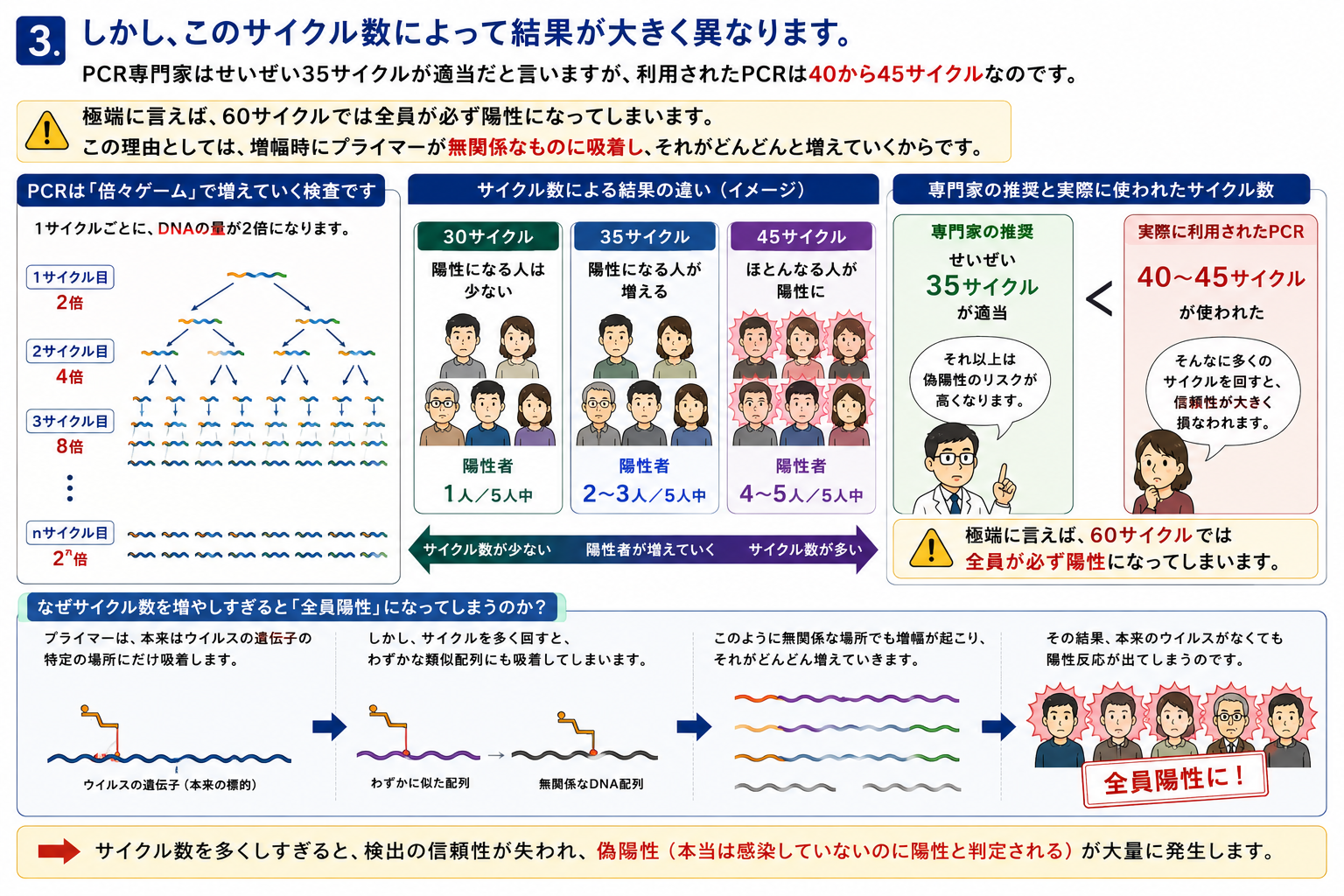
3.しかし、このサイクル数によって結果が大きく異なります。PCR専門家はせいぜい35サイクルが適当だと言いますが、利用されたPCRは40から45サイクルなのです。極端に言えば、60サイクルでは全員が必ず陽性になってしまいます。この理由としては、増幅時にプライマーが無関係なものに吸着し、それがどんどんと増えていくからです。
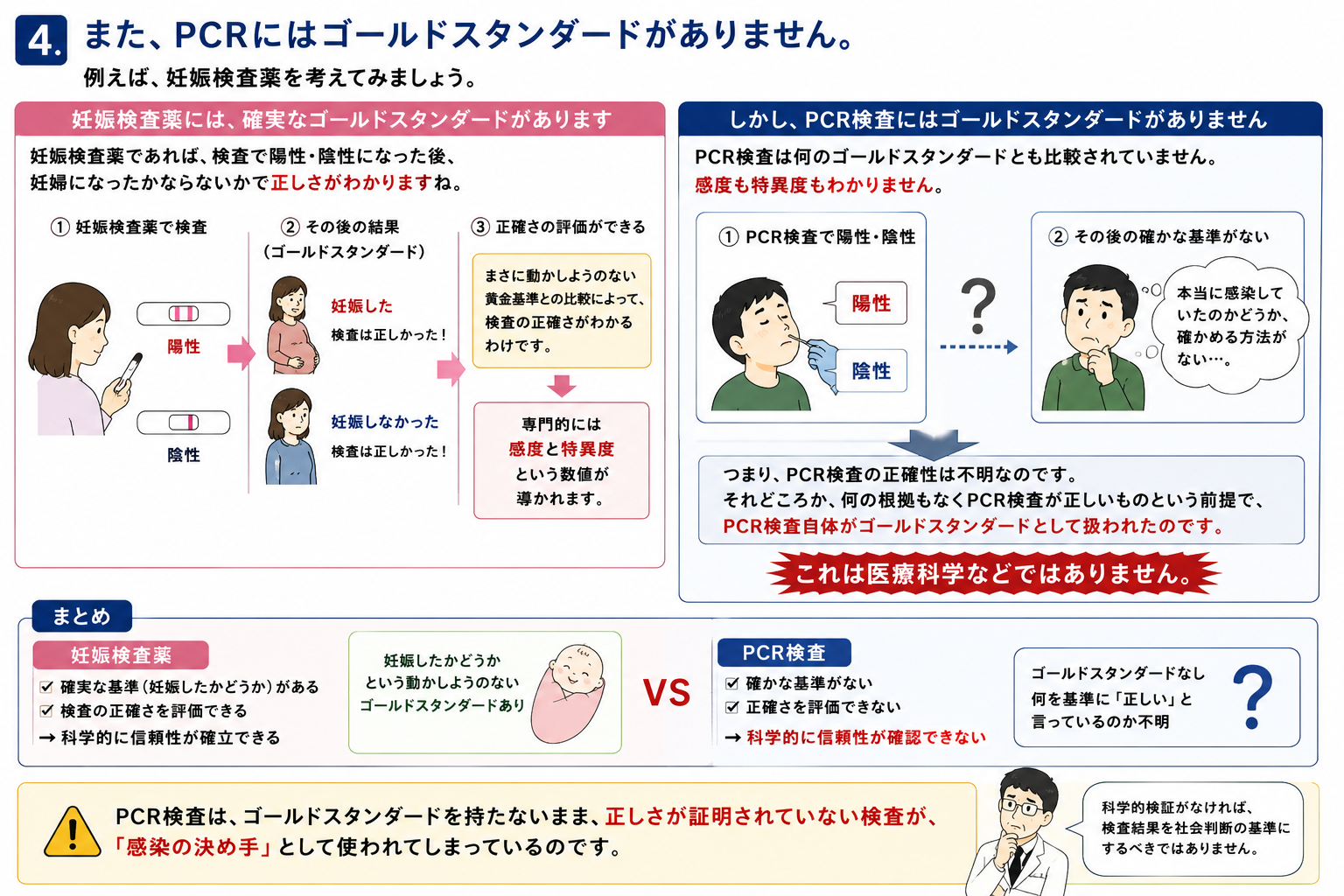
4.また、PCRにはゴールドスタンダードがありません。例えば、妊娠検査薬を考えみましょう。妊娠検査薬であれば、検査で陽性・陰性になった後、妊婦になったかならないかで正しさがわかりますね。まさに動かしようのない黄金基準との比較によって検査の正確さがわかるわけです。専門的には感度と特異度という数値が導かれます。
しかし、PCR検査は何のゴールドスタンダードとも比較されていません。感度も特異度もわかりません。つまり、PCR検査の正確性は不明なのです。それどころか、何の根拠もなくPCR検査が正しいものという前提でPCR検査自体がゴールドスタンダードとして扱われたのです。これは医療科学などではありません。
5.さらに、この検査はもともとの約3万のウイルスゲノムが正しいという前提に立っていますが、このウイルスゲノム配列の導出の仕方も到底科学とは言えないものです。これについては別項で説明します。
Fan Wu論文のインチキぶり
Fan Wu論文とは『A new coronavirus associated with human respiratory disease in China』というもので、世界で初めて「新型コロナウイルスのゲノム」を発見(?)したことを報告する論文です。
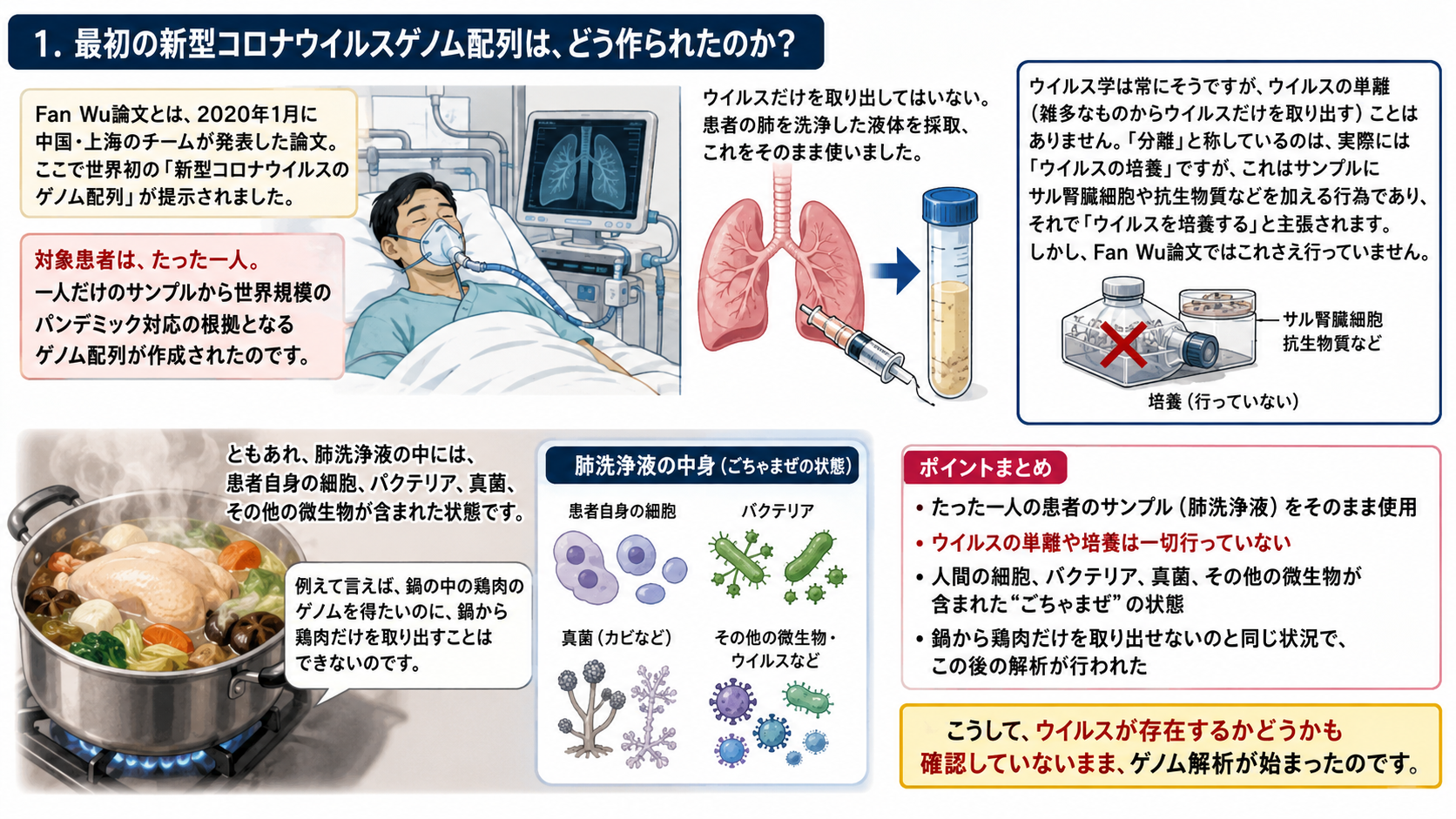
1.最初の新型コロナウイルスゲノム配列は、どう作られたのか?
Fan Wu論文とは、2020年1月に中国・上海のチームが発表した論文。ここで世界初の「新型コロナウイルスのゲノム配列」が提示されました。
対象患者は、たった一人。一人だけのサンプルから世界規模のパンデミック対応の根拠となるゲノム配列が作成されたのです。
ウイルスだけを取り出してはいない。患者の肺を洗浄した液体を採取、これをそのまま使いました。
ウイルス学は常にそうですが、ウイルスの単離(雑多なものからウイルスだけを取り出す)ことはありません。「分離」と称しているのは、実際には「ウイルスの培養」ですが、これはサンプルにサル腎臓細胞や抗生物質などを加える行為であり、それで「ウイルスを培養する」と主張されます。しかし、Fan Wu論文ではこれさえ行っていません。
ともあれ、肺洗浄液の中には、患者自身の細胞、バクテリア、真菌、その他の微生物が含まれた状態です。例えて言えば、鍋の中の鶏肉のゲノムを得たいのに、鍋から鶏肉だけを取り出すことはできないのです。
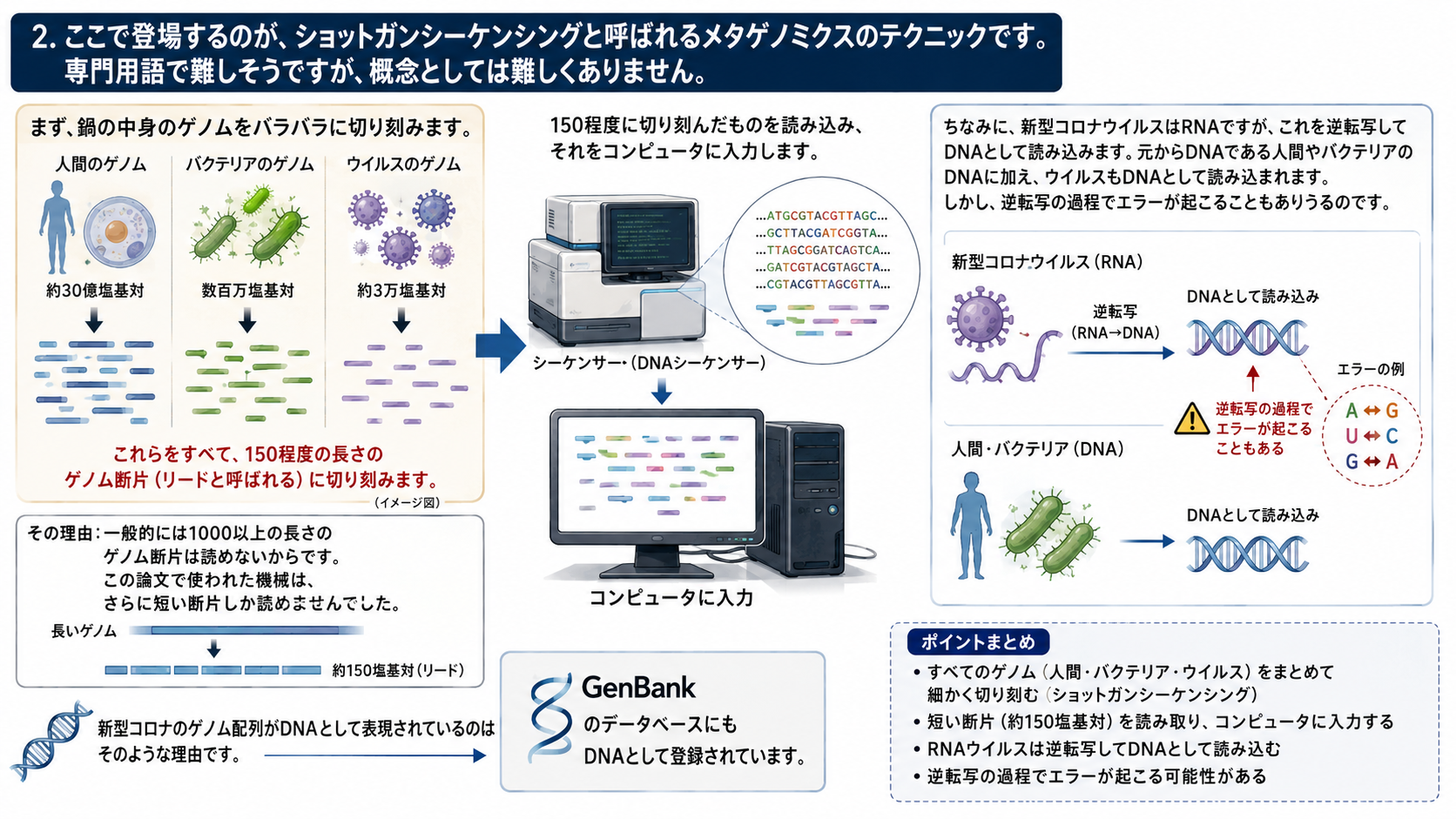
2.ここで登場するのが、ショットガンシーケンシングと呼ばれるメタゲノミクスのテクニックです。専門用語で難しそうですが、概念としては難しくありません。
まず、鍋の中身のゲノムをバラバラに切り刻みます。30億の長さの人間のゲノムも、数百万のバクテリアのゲノムも、3万のウイルスのゲノムも、150程度の長さのゲノム断片(リードと呼ばれる)に切り刻みます。
その理由としては、一般的には1000以上の長さのゲノム断片は読めないからです。この論文で使われた機械はさらに短い断片しか読めませんでした。そこで、150程度に切り刻んだものを読み込み、それをコンピュータに入力します。
ちなみに、新型コロナウイルスはRNAですが、これを逆転写してDNAとして読み込みます。元からDNAである人間やバクテリアのDNAに加え、ウイルスもDNAとして読み込まれます。しかし、逆転写の過程でエラーが起こることもありうるのです。
新型コロナのゲノム配列がDNAとして表現されているのはそのような理由です。GenBankのデータベースにもDNAとして登録されています。
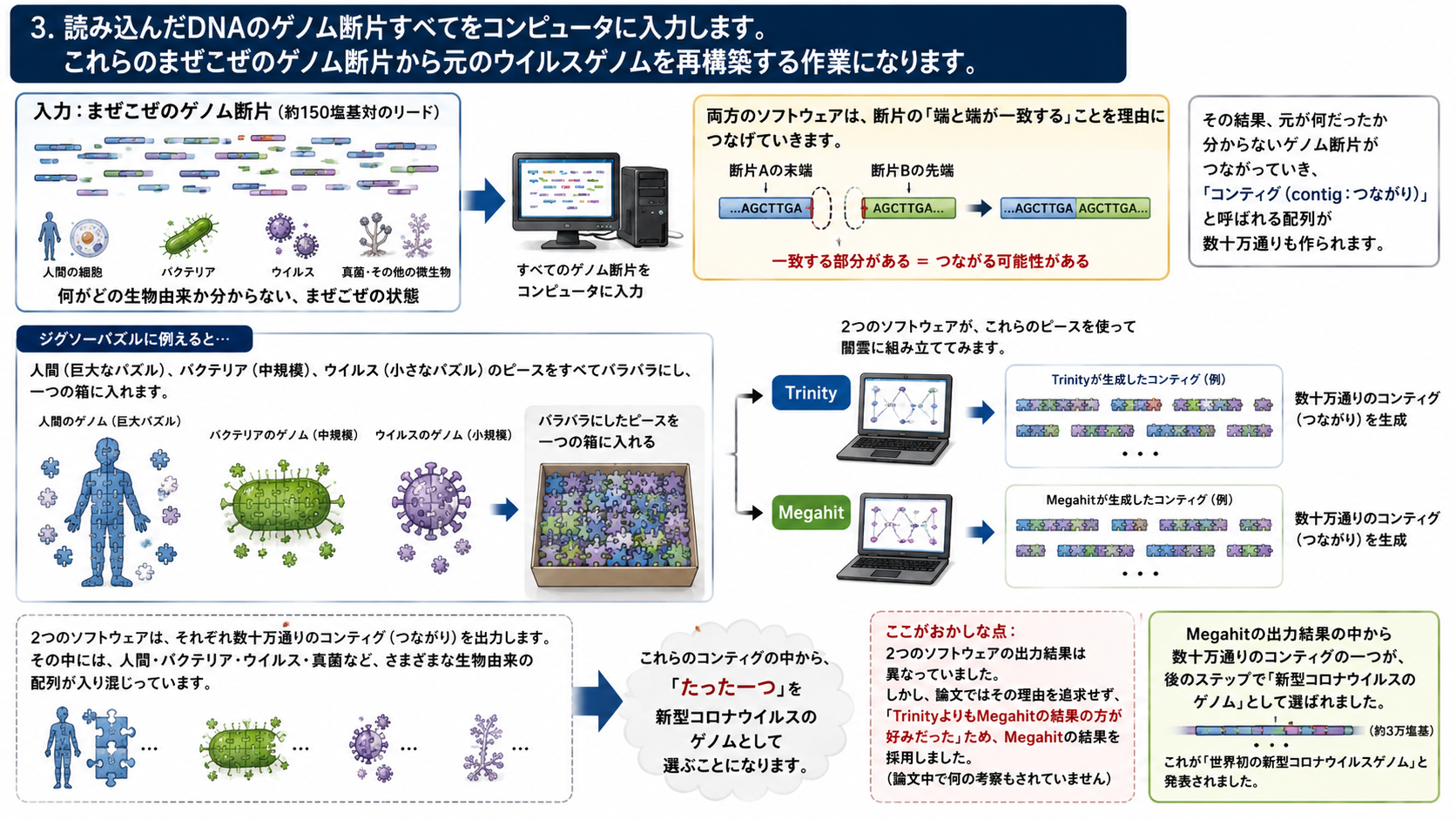
3.ともあれ、読み込んだDNAのゲノム断片すべてをコンピュータに入力します。この後は、純粋にコンピュータ的な処理ですが、これらのまぜこぜのゲノム断片から元のウイルスゲノムを再構築する作業になります。
この作業には、TrinityとMegahitという二種類のソフトウェアが使われました。これらのソフトウェアは、もともと何だったかわからないゲノム断片を端と端が一致するという理由でつなげるのです。その一つ一つはコンティグと呼ばれます。コンティグ、つまりつながりは数十万通りにもなります。
例えば、ジグソーパズルを考えてみましょう。人間を表す巨大なジグソーパズル、バクテリアの中規模のジグソーパズル、ウイルスの小さなジグソーパズルのピースをすべてバラバラにし、一つの箱の中に入れます。
2つのソフトウェアは、これらのピースを使って闇雲に組み立ててみます。先の通り、つながり方(コンティグ)は数十万通りにもなります。
2つのソフトウェアが生成した、それぞれ数十万のコンティグの中から、ただ一つが新型コロナウイルスのゲノムとして選ばれました。一体どうやったのでしょう?
まず、ここがおかしな点ですが、2つのソフトウェアが出力した結果は異なっていました。しかし、彼らはその理由を追求せず、TrinityよりもMegahitが出力した結果の方が彼らの好みだったため、Megahitの結果を採用したのです。これについては、論文中で何の考察もされていません。
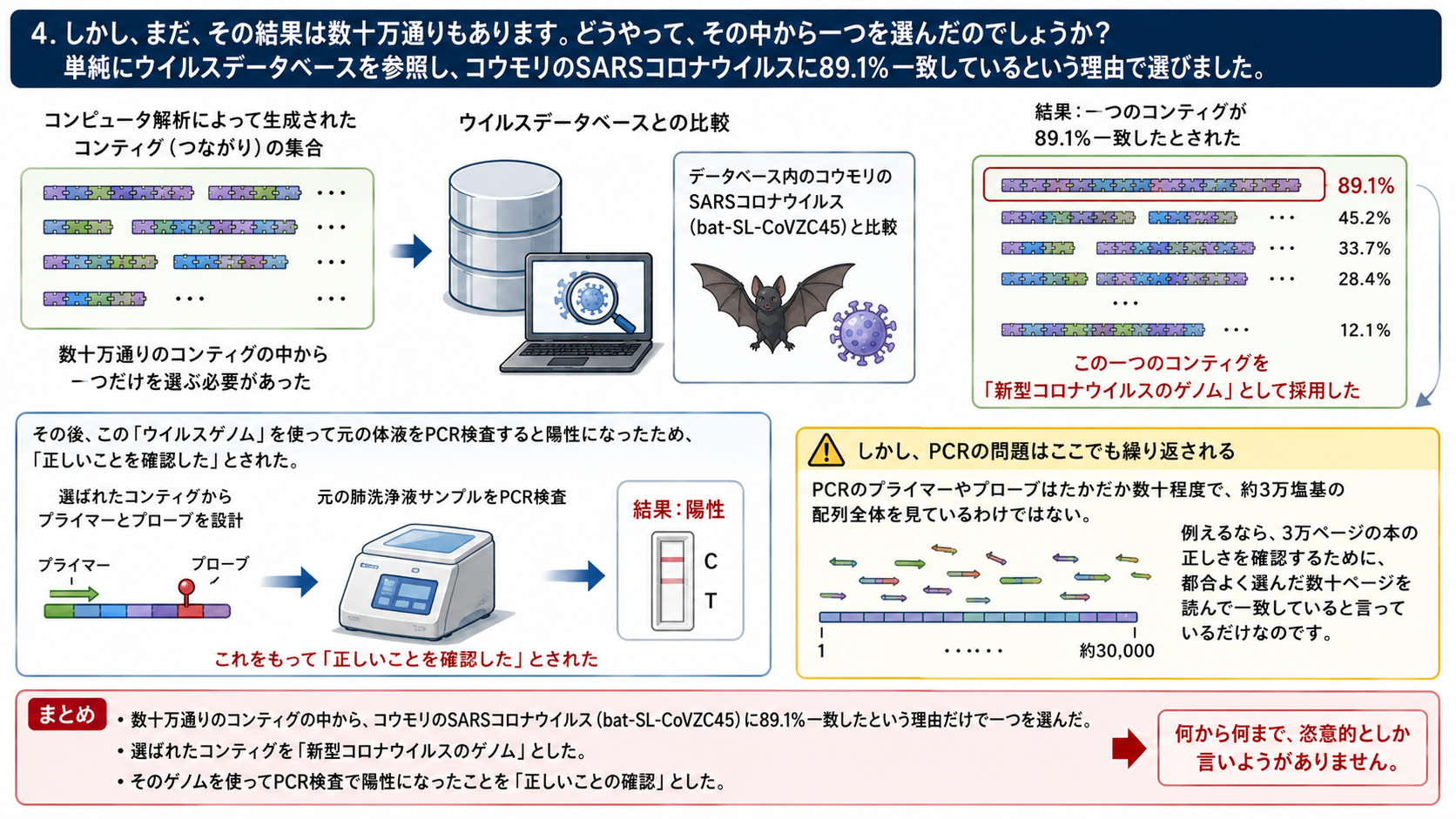
4.しかし、まだ、その結果は数十万通りもあります。どうやって、その中から一つを選んだのでしょうか?
単純にウイルスデータベースを参照し、コンティグの中の一つが、コウモリのSARSコロナウイルス(bat-SL-CoVZC45)に89.1%一致しているという理由で選んだのです。何から何まで恣意的としか言いようがありません。
そして、できあがった「ウイルスゲノム」を使い、元の体液をPCR検査してみると陽性になったという理由で、「正しいことを確認した」というわけです。
もちろん、先に述べたPCRの問題がここでも繰り返されます。PCRのプライマーやプローブはたかだか数十程度で約3万の配列全体を見つけたわけではありません。
例えていうなら、3万ページの本の正しさを確認するために、都合よく選んだ数十ページを読んで一致していると言っているだけなのです。
どうでしょうか?これがFan Wuらの作成した「世界初の新型コロナウイルスゲノム」の正体です。
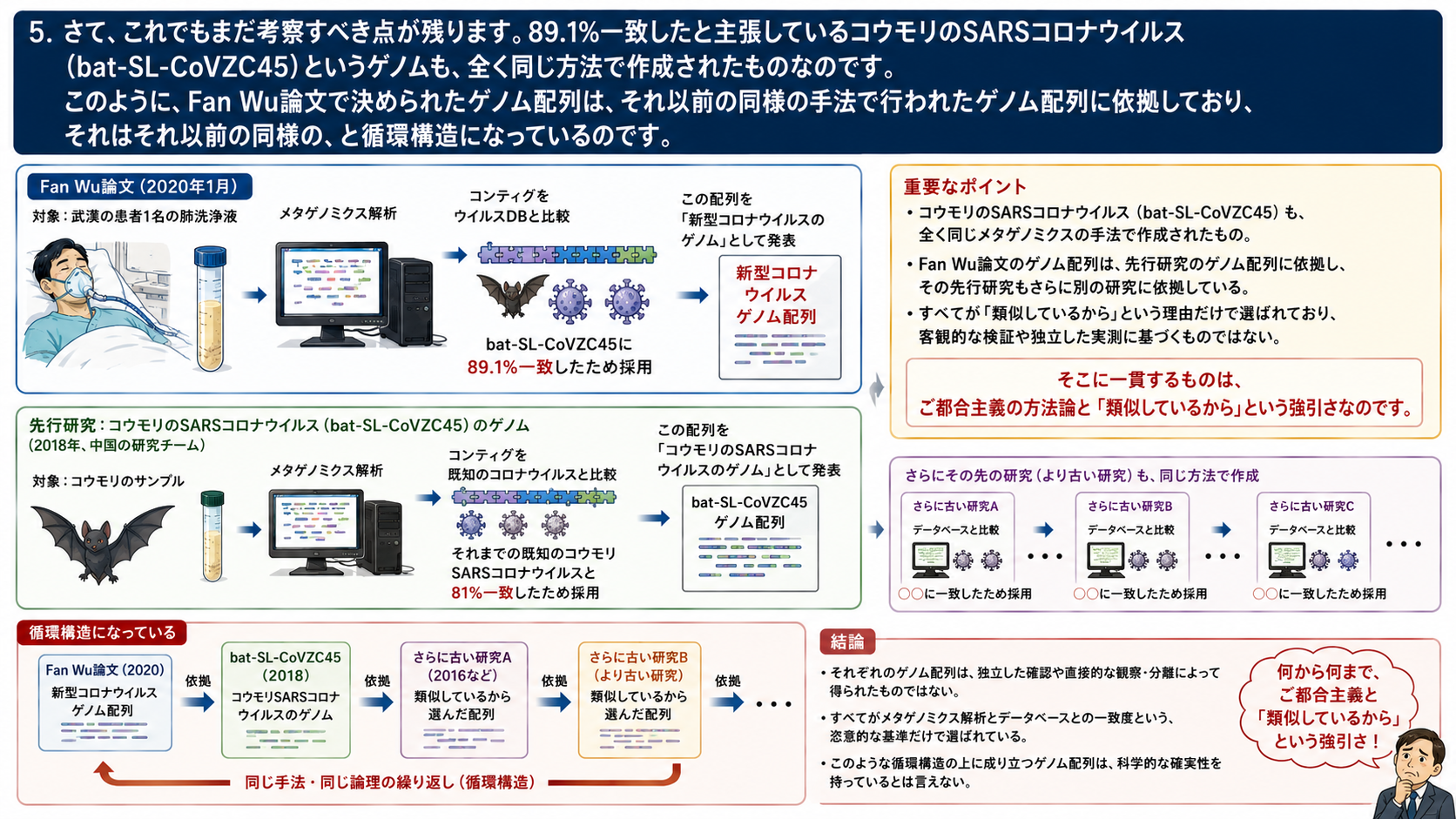
5.さて、これでもまだ考察すべき点が残ります。89.1%一致したと主張しているコウモリのSARSコロナウイルス(bat-SL-CoVZC45)というゲノムも全く同じ方法で作成されたものなのです。2018年に中国研究チームが発表したものですが、これもまた、その時点での既知のコウモリSARSコロナウイルスと81%の同一性を持つという理由で選ばれた配列なのです。
このように、Fan Wu論文で決められたゲノム配列は、それ以前の同様の手法で行われたゲノム配列に依拠しており、それはそれ以前の同様の、と循環構造になっているのです。そこに一貫するものはご都合主義の方法論と「類似しているから」という強引さなのです。
「ウイルスの写真」なる正体不明の物体
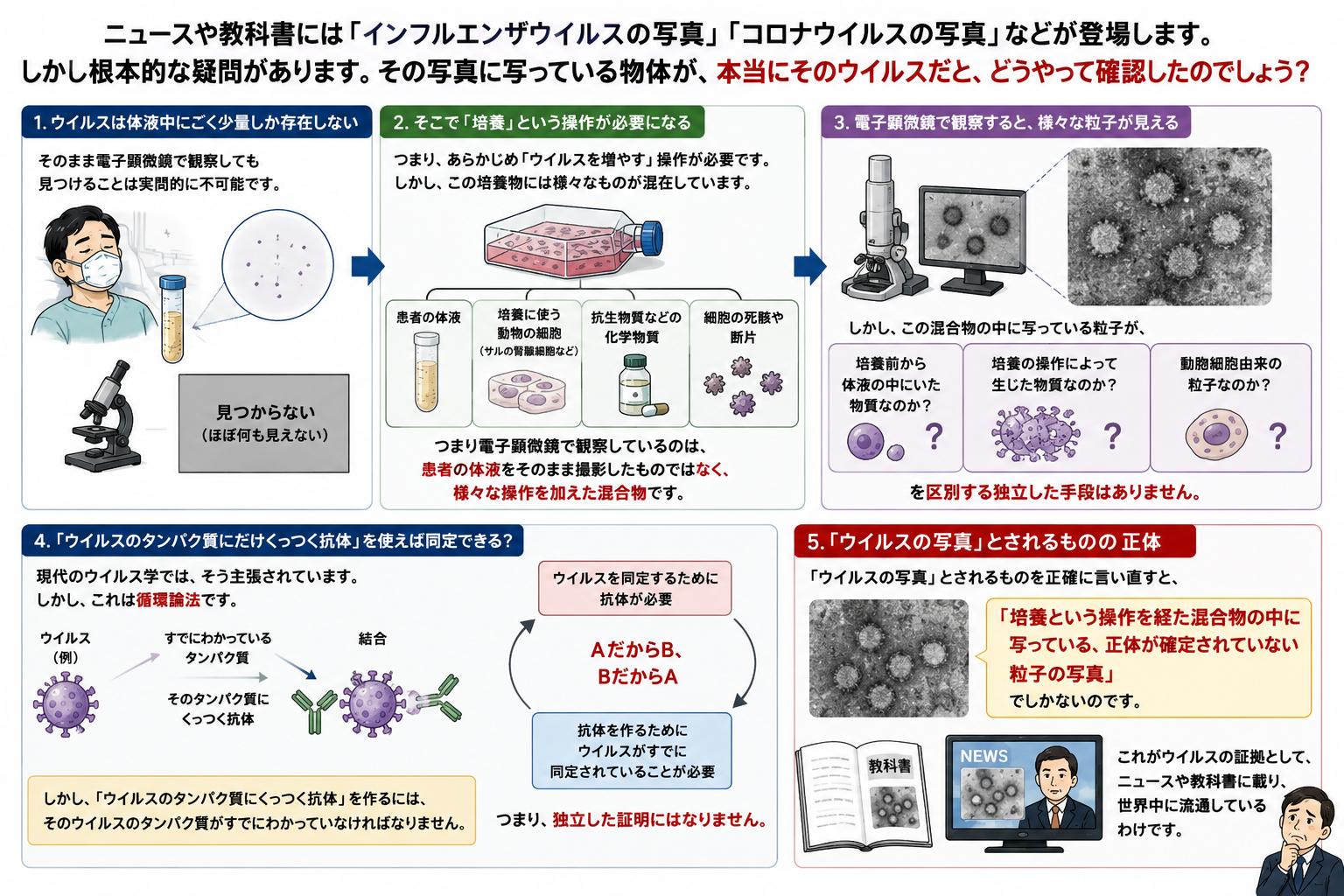
ニュースや教科書には「インフルエンザウイルスの写真」「コロナウイルスの写真」などが登場します。しかし根本的な疑問があります。その写真に写っている物体が、本当にそのウイルスだと、どうやって確認したのでしょう?
ウイルスは体液の中に極めて少量しか存在しないため、そのまま電子顕微鏡で観察しても見つけることは実質的に不可能とされています。そこでまず「培養」という操作が必要になります。つまり、あらかじめ「ウイルスを増やす」操作が必要です。しかし、この培養物には様々なものが混在しています。
- 患者の体液
- 培養に使う動物の細胞(サルの腎臓細胞など)
- 抗生物質などの化学物質
- 細胞の死骸や断片
つまり電子顕微鏡で観察しているのは、患者の体液をそのまま撮影したものではなく、様々な操作を加えた混合物です。
しかし、この混合物の中に写っている粒子が、
- 培養前から体液の中にいた物質なのか
- 培養の操作によって生じた物質なのか
- 動物細胞由来の粒子なのか
を区別する独立した手段はありません。
もっとも、現代のウイルス学では「ウイルスのタンパク質にだけくっつく抗体」を使い、写っている粒子を同定できるといいます。しかしこれは循環論法なのです。「ウイルスのタンパク質にくっつく抗体」を作るには、そのウイルスのタンパク質がすでにわかっていなければなりません。つまり、ウイルスを同定するために使う道具が、すでに同定されたウイルスを前提にしています。これは「AだからB、BだからA」という説明の輪であり、独立した証明にはなりません。
「ウイルスの写真」とされるものを正確に言い直すと、「培養という操作を経た混合物の中に写っている、正体が確定されていない粒子の写真」でしかないのです。これがウイルスの証拠としてニュースや教科書に載り、世界中に流通しているわけです。
世界中で確認されているからウイルスは存在する
1.さて、Fan Wuらが新型コロナウイルスのゲノムを発表して以降、世界中で我も我もと研究者が患者を見つけてはそのゲノム配列を取得したわけですが、これがどれもFan Wuのものにほぼ一致する配列だったわけです。
新型コロナウイルスが現実に存在し、世界中に蔓延しているという誤解のもとにもなったわけですが、ここではこのトリックを暴いていきます。
まず、研究者のやっていることはFan Wuとほとんど同じです。患者の体液を得て、その内容物のゲノムを一緒くたに切り刻み、おそらくは同じく150程度のゲノム断片にし、コンピュータに入力します。
ここからが問題です。Fan Wuは、そのジグソーパズルのピースを使い、2つのソフトウェアを用いてあらゆる組み合わせを試しましたが、後続の研究者はそんなことしません。ですから、ゲノム配列の構築は、極めて簡単になります。
2.どうやるかと言えば、Fan Wuの配列を見ながら、その通りにゲノム断片を並べていくだけなのです。これならFan Wuの配列に似たものになるのは当然すぎるほど当然です。
別の例えをするならば、Fan Wuがレゴブロックでお城を作ったので、他の研究者はそのお城を見ながら手持ちのレゴブロックで同じようなお城を作るというだけの話です。
しかし、時にはFan Wuの配列の通りに並べようと思っても、パズルピースが足りなくなったり、違う配列になってしまうこともあるわけです。前者はソフトウェアが統計的に補完します。後者は「ウイルスが変異した」となります。
3.もちろん、これらの後続の研究者はデノボアセンブリをすることもあります。これは、Fan Wuの配列を見ずに、つまり、それがなかったものとして、新たにゲノム配列を作るということです。しかし、結局のところ、過去データベースにある程度一致するものを選ぶというのには変わりはなく、そこで「新型コロナウイルスのゲノム配列」に似たものが選ばれるというだけの話です。
つまり、ソフトウェアで作成した無数の中の一つを選ぶのに、ウイルスデータベースに登録済みのFan Wuあるいは他の研究者のゲノム配列を見て、それと同じようなものを選ぶというだけの話です。
結局のところ、「世界中で新型コロナウイルスのゲノムが発見された」という事実は、世界中でFan Wu配列と同じようなものを選んだという結果にすぎないのです。
コメント